Spotify,为什么音乐软件总能猜到我口味?
Spotify 也是译者最喜欢的音乐软件了,和这篇文章的作者一样,对于 Sptify 的喜爱大多归功于其音乐推荐系统,那简直就是一个百宝箱,你总能听到自己喜欢的歌曲。这篇文章虽然是一篇技术文,但是读起来并不费劲,希望你能通过此文了解一些推荐系统背后的秘密。

对于音乐应用软件 Spotify 的用户来说,每周一都会收到 Spotify 的「每周推荐」(Discover Weekly)——包含了30首各种风格但你从未欣赏过的歌曲混杂,神奇的是每一首对你来说都是珍品。
Spotify 是我最钟意的音乐应用了,尤其是它的 Discover Weekly 。让我觉得它是那么的了解我,它比任何人都要了解我的音乐品好,每一周的推荐音乐都令我十分满意。我感觉不到它的存在,却又觉得它无处不在。
如果你也是为音乐狂的话,且让我来好好向你介绍一下我最好的虚拟音乐伙伴:
我的 Discover Weekly 页面
事实证明,并不是只有我一个人沉迷于 Discover Weekly ,它有着大量的拥趸,甚至于 Spotify 因为这个功能大受欢迎而重新思考商业模式,投入大量的资源来推荐基于算法的音乐列表。
自从2015年Spotify推出 Discover Weekly 之后,我就开始了解它的工作机理(我同时也是Spotify 的粉丝,有时候我会把自己当成该公司的产品经理来研究这个产品)。
经过了三个星期的研究发现,我很高兴能够了解到一些帷幕背后的那股“神秘力量”。
那么 Spotify 究竟是如何向每个用户推荐那30首音乐的呢?
先让我们来了解一下音乐推荐的历史发展历程,来看看其他音乐公司是如何推荐音乐的,之后我们再来对比一下 Spotify 能够从中胜出的缘由。

早在2000年,Songza 就开始了音乐推荐,不过那时候是人工挑选歌曲凑成歌单推荐给用户,Songza 会邀请一些音乐方面的行家来做歌单。这就不可避免地造成了歌单实际上代表了“专家们”的品味,而且也不能满足每个人音乐品好的细微差别。
和 Songza 一样,身为音乐推荐领域的早期玩家, Pandora 也有着自己的音乐推荐系统。和 Songza 不同,Pandora 会让用户用关键词来描述每一首歌曲,然后给这些歌曲打上相应的标签,随后会用代码简单筛选一下歌曲,让相似的音乐组成歌单推荐给用户。
在同一时期,一个来自麻省理工媒体实验室的一家音乐公司——The Echo Next 诞生了。
The Echo Next 彻底地颠覆了整个音乐推荐领域,让音乐推荐向个性化迈进了一大步。The Echo Next 用算法来分析歌曲的旋律和文本,从而实现音乐识别、个性化推荐、歌单创建和音乐分析。
Last.fm 则采用了一种叫做「协同过滤」的一种方法来挑选用户可能喜欢的音乐,并且至今都在升级使用。
以上是其他音乐软件的推荐系统的简介,那么 Spotify 是如何构建自己的推荐系统的,它是如何从中脱颖而出的呢?
Spotify 的三种推荐模型
事实上, Spotify 并不是只用了一种推荐方法,它综合了其他音乐软件使用的几种最好的推荐策略构成了它独一无二强大的推荐系统。
在 Discover Weekly 背后, Spotify 使用了三种主要的推荐模型:
- 协同过滤(上面介绍Last.fm的时候提到过),主要工作机理是分析你的用户行为和其他人的用户行为。
- 自然语言处理,用来处理分析文本。
- 音频模型,用来处理音乐源文件音轨和声道。
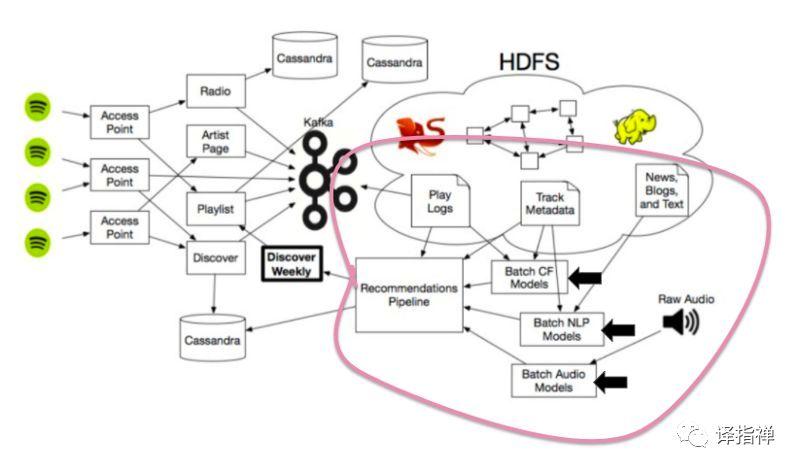
Spotity 推荐系统简略图
下面我们来较为详细地了解一下每一种推荐模型:
1. 协同过滤
一提到「协同过滤」,可能更多的人想到的是 Netflix 。Netflix 是第一家采用协同过滤技术来搭建推荐系统的公司,它们使用评分制度来了解用户,进而推荐给用户和他们喜好相似的用户喜欢的影片。
自从 Netflix 采用协同过滤并取得成功之后,几乎所用评分制的推荐系统都采用了这种技术。
和 Netflix 不同,Spotify 并没有与之类似的评分制度。事实上,Spotify 通过一些隐性反馈——比如我们是否会把某首歌曲保存起来,或者是我们在听完一首歌曲之后是否会浏览歌手的主页。
但究竟什么是协同过滤,它是如何工作的?
下面有一张生动的图片可以回答这个疑问:

Spotify “协同过滤”
上面这两个人都有自己喜欢的歌曲:一个喜欢P,Q,R和S,另一个喜欢Q,R,S和T,协同过滤系统就会利用这些数据。
“你们两个喜欢的四首歌曲当中有三首是相同,所以你们很有可能是品好相似的用户。所以你们有很大的概率喜欢对方喜欢自己却没有听过的音乐内容。”
之后协同过滤系统就会给第一位用户推荐歌曲P,给第二位用户推荐歌曲T。
那么 Spotify 是如何通过这些概念做到利用百万用户的音乐偏好来给其他海量的用户推荐音乐的呢?
通过算法,利用python的函数库来实现。
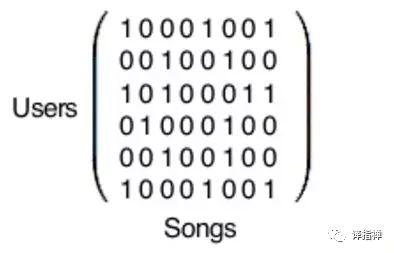
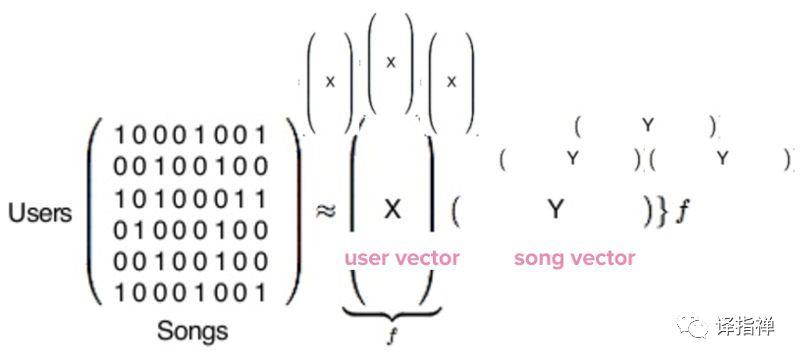
上图表示的是用户-歌曲矩阵,事实上,真正的用户-歌曲矩阵是巨大的。每一行代表一位用户,一共有1.4亿行(如果你使用 Spotify 的话,那么你就是其中一行);每一列代表着 Spotify 数据库中的3千万歌曲。之后,python 代码会处理矩阵,将其进行因式分解。
![]()
复杂的数学式
处理完之后,我们将会得到两种类型的向量:X和Y。X称为用户向量,代表了每一名用户的音乐品好;Y称为歌曲向量,描述了每一首歌曲的内容。
用户-歌曲矩阵
现在我们得到了1.4亿个用户向量和3千万个歌曲向量,这些向量对于用户来说就是没有用的数字,但是对于这家公司来说,却是威力无比。
为了了解我的音乐品好,可以通过把代表我的向量和其他所有用户进行对比,进而找到和我趣味相投的人。对于代表歌曲的向量也同样适用,比较所有歌曲向量,你可以找到相似程度高的相关音乐。
协同过滤已经足够有用,但是 Spotify 通过引入其他方式来让推荐系统变得更好。
2. 自然语言处理
Spotify 的第二种主要推荐模型叫做自然语言处理,自然语言处理所应用的数据资源全部来自于互联网——访问记录,网上新发表的文章,博客和其他网上的一些文本信息。

自然语言处理——计算机了解人类语言的方式——其本身就是一门广阔的学问。
由于文章篇幅,我不能在这里详细介绍自然语言处理背后的详细原理,但是我可以给你一个通俗的解释:Spotify 会爬取网上的各种音乐资讯。
乐评人写的博客,音乐爱好者发的文章……通过这种方法来了解当下人们在讨论什么样的音乐,在评论时他们使用了什么样的语言描述他们的感受,并且还会发现风格相似的音乐人和歌曲。
Spotify 具体是如何运用自然语言处理的我并不知道,但是我可以向你介绍一下 The Echo Nest 是如何使用它的:他们把网络资讯打包成一个叫做“文化向量”(cultural vectors)或“重要关键字”(top terms)。
每一位艺术家和歌曲有着成百上千的关键词,并且每天都是变化的。每一个关键字都有自己的权重,权重越高就代表这个关键字越能描述这为艺术家或这首歌曲。
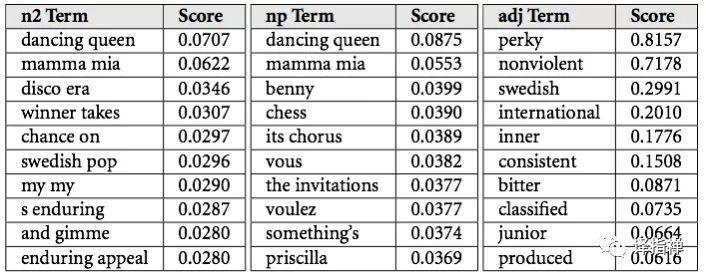
cultural vectors /top terms
之后,和协同过滤相似,自然语言处理会把这些关键字和权重处理为向量模式,然后判断音乐之间的相似性。
3. 原始音频模型
首先,你可能会问:我们已经从前两种处理模型当中获取了那么多的数据,为什么还要引入第三种推荐模型?
- 第一,引入原始音频模型可以提高整个推荐模型的准确性。
- 第二,但是真正的意义之所在,和前两种模型形式不同,原始音频模型可以处理新发行的音乐。
假如,你有一位音乐唱作者朋友在Spotify发表了他的新作,但是只有50名用户听了这首歌。在这种情况下,Spotify 就收集不到足够的信息用来「协同过滤」。
在网上也找不到任何关于这首歌曲的相关描述,自然语言处理也就涉及不到。好在的是原始音频处理能够识别新发表的作品和流行作品音轨之间的不同,这样一来,你朋友的作品将有可能和流行歌曲一起被收录到 Discover Weekly 中。
下面我们就来看看原始音频模式究竟是如何工作的。
答案是卷积神经网络,卷积神经网络也可用于面部识别技术。在 Spotify 的例子当中,卷积神经网络用来处理音频数据而不是像素。
下面有一张卷积神经网络模型的实例样图:
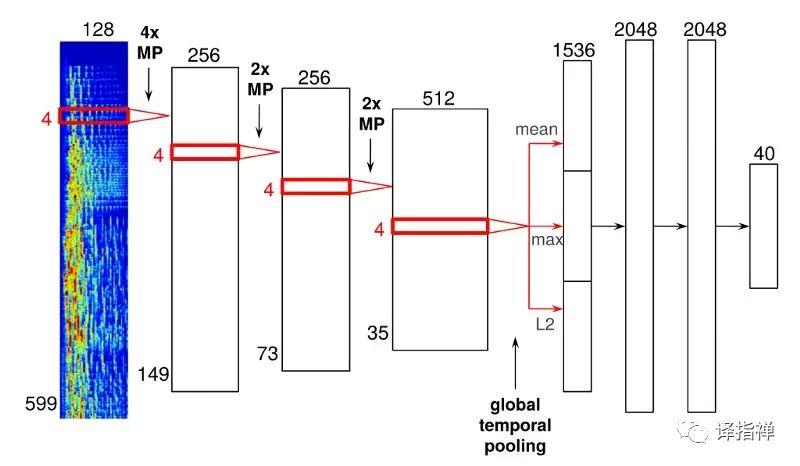
如图所示,左边四个较粗的竖条代表四个卷积层,右边三个较细的竖条代表了密集层。向卷积层中输入代表音乐模型的时间频率,这些从频谱中分离出来的时间频率将会被串联起来。
音乐模型将会通过这些卷积层,在最后一个卷积层之后,你会看到一个全局时间池层(global temporal pooling layer),它将会贯穿整个时间轴,不停计算音乐中每一刻的频率特性。之后,卷积神经网络将会“弄懂”整首音乐,包括音乐中的拍子记号、音调、风格、节奏等。
下面这幅图就是 Daft Punk 的《Around the World》 截选30秒的片段的音乐特性:
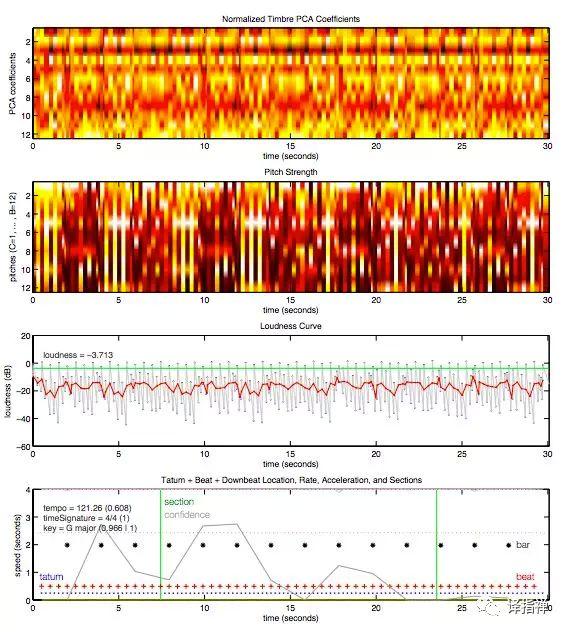
最终,因为Spotify 掌握了这些最根本的音乐特性,它才能发现音乐之间的相似性,给用户推荐和他们历史记录中相似的音乐。当然,这三种推荐模型只是整个推荐系统中的一部分,还有其他比如储存大量数据的数据库,处理庞大矩阵和音乐资讯的机器等等。
最后,我希望我写的这些能够为你提供有用的信息,并且可以满足你的好奇心。现在,我要去欣赏 Discover Weekly 推荐给我的音乐了!